
Securing Your Visual Content Against Unauthorized Replication by AI-Powered Design Programs
Securing Your Visual Content Against Unauthorized Replication by AI-Powered Design Programs
Quick Links
- How to Protect Copyrighted Art from AI
- Can AI Art Be Copyrighted?
- Can AI Art Generators Use My Copyrighted Art?
- Upcoming Tools May Help Defeat AI Art Generators
- Rise of the Robots
Key Takeaways
You can try a few things to protect your art from AI generators:
- Opt-out of training datasets with a tool like HaveIBeenTrained.com.
- Use a “robots.txt” file to ward off web crawlers, many of which are used to create datasets in the first place.
- Copyright your artwork and challenge the developers of these tools in court (or joing existing class-action lawsuits).
- Only upload aggressively watermarked images.
- Avoid putting your art on the internet in the first place.
AI art generators might not be able to ape human creativity, but they sure can rip you off. This is a worry for both artists and those who dread the AI takeover, but all may not be lost.
How to Protect Copyrighted Art from AI
AI art generators are nothing without the datasets on which they’ve been trained. This involves taking a huge sample of existing artwork and contextualizing it in a way that allows humans to use natural language prompts to create similar artwork. You can try it for yourself using a generative art app like OpenAI’s DALL-E 2 or Midjourney .
We asked DALL-E 2 to produce “a picture of Elmo from Sesame Street in the style of Pablo Picasso” and here’s what we got (yes, this was the best of the bunch):

Being able to create artwork in the style of dead artists might not raise too many alarm bells, particularly in a style that’s so recognizable. But for modern artists who share their creations via the likes of ArtStation, DeviantArt, Behance, personal websites, and social media pages like Instagram or Facebook, it’s far more concerning.
So what can you do to protect your own creations from being used to train an AI that can spit out creations far faster than you can?
Opt Out of Training Datasets
You can choose to opt out of two of the largest open image training datasets on the internet, LAION-400M and LAION-5B using HaveIBeenTrained.com . These datasets are used by some of the biggest image generators on the web including Stable Diffusion and Google Imagen. Because they’re truly open, many other generative AI tools use them also.
Unfortunately, the process of doing this is slow and tedious. You’ll need to first sign up for an account and then search or upload an image to find matches within the dataset. You can then right-click on the image in your desktop web browser and choose the “Add to My Opt-Outs” option. Alternatively, you can give the dataset explicit permission to use an image by clicking “Add to My Opt-Ins” instead.
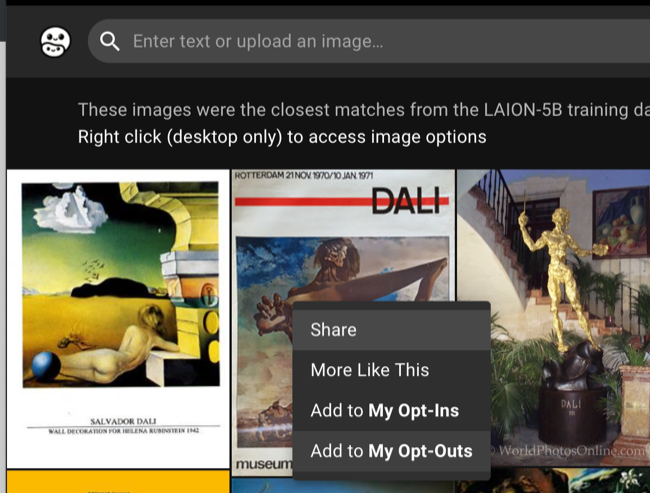
You’ll need to do this for each image you find, so it can be a painstaking process if you’re an artist with a large body of work. How long it will realistically take ultimately depends on how easy it is to filter out your work, which might be easier if you have work associated with a unique name or project, a large online following, and so on.
Though these two massive datasets are a great place to start, they’re far from the only ones that are used. Individuals can create their own datasets, and some do to replicate a particular artist or art style. Some companies like OpenAI don’t disclose which datasets their tools use at all, so there’s no way to combat these.
Use Robots.txt to Ward Off Crawlers
A robots.txt file is a small text document that is placed in the root directory of a website to tell web crawlers where they are allowed or not allowed to go. Though Google explicitly states that “it is not a mechanism for keeping a web page out of Google” you may still want to try and use it to keep web crawlers away from your artwork if you’re hosting it on your own website.
As the name may suggest, web crawlers crawl the web in search of content for indexing. Search engines are far from the only crawlers, and crawlers are also used to create datasets much like the LAION-400M and LAION-5B datasets mentioned above. The main problem with robots.txt is that it relies on the web crawler respecting your request.
One of the largest datasets around is Common Crawl , data from which has been used to construct LAION’s datasets. The process of crawling the web is an ongoing one, with LAION stating its current (at the time of writing) LAION-400M dataset has been created “from random web pages crawled between 2014 and 2021.”
Common Crawl states that it respects robots.txt and the Robots Exclusion Protocol both in terms of blocking content and delaying crawling (to save on bandwidth). You can do this by creating a rule for the “CCBot” user agent in your Robots.txt file. Of course, none of this will help if you’re not self-hosting your artwork.
Google Search Central has a handy guide for creating a robots.txt file, or you can use a website like Ryte’s Robots.txt Generator to create one for you. You can allow or disable specific user agents from specific directories, or simply block everything with a wildcard (*). For example, a robots.txt file that blocks all files in your /images/ directory from Common Crawl while still allowing other crawlers to index your website would read:
User-agent: CCbot
Disallow: /images/
User-agent: *
Allow: /
Sitemap: https://www.example.com/sitemap.xml
This won’t defeat crawlers that have already visited your website, but it should prevent Common Crawl from indexing your /images/ folder (and any new uploads since the last crawl) in the future.
Copyright Your Artwork
Though copyright is implied in work that you have created, going out of your way to copyright your work may be worth the effort too. In the US you can do this by registering your works over at Copyright.gov . You can submit up to 10 unpublished works in a single application, just be aware that it can take a while (at present around a year) for your works to be processed.
Having registered copyright to your work gives you more of a leg to stand on in matters that involve the courts. That’s the idea behind a class-action lawsuit filed against Stability AI (developer of Stable Diffusion and DreamStudio, funder of LAION), DeviantArt (a platform for artists and developer of DreamUp), and Midjourney, a generative art app on behalf of affected artists.
You can read all about the lawsuit at StableDiffusionLitigation.com , and if you believe your work has been used to train these generators then you may have grounds to join the class action by reaching out to the legal team. Having applied to have your art registered with the U.S. Copyright Office is an important first step if you want to go down this route.
Like other practices that have attracted lawyers in the past—piracy, jailbreaking, filesharing—it’s unlikely that a lawsuit will stop the practice altogether. The defense will likely argue that these tools were trained on “fair use” material gathered from public-facing websites. We’ll have to wait and see to find out what effect lawsuits like these will have if any.
Aggressive Watermarking
If you only ever upload your artwork with some aggressive or borderline self-destructive watermarking present, artwork included in datasets will reflect this. Ultimately this depends largely on why your artwork is being uploaded in the first place. If you’re creating artwork non-commercially for the enjoyment of the internet, this seems ultimately self-defeating.

Tim Brookes / How-To Geek
However, if you’re selling real-world paintings and want a means of exhibiting them online prior to sale, it may help somewhat. It’s certainly going to detract from the finished artwork, so it’s something you’re going to have to consider for yourself.
Don’t Upload Your Art on the Internet
This might sound ridiculous (and it is) but if your artwork is never uploaded to the internet in the first place, there’s no chance it will be caught in the net and used to train AI. Of course, making a living as an artist without using the internet to share your artwork might be near-impossible (especially if you work in a digital medium).
For artists working on music, this is an impossibility. Even if you work with traditional materials like oil or watercolor there’s no telling whether someone is going to snap a picture of a finished piece and upload it themselves.
Can AI Art Be Copyrighted?
The question of whether the output of generative AI can be copyrighted is a complex one. One thing that is generally accepted is that the AI tool used to generate the art rarely has any rights to the output.
This is clearly stated in the terms of service of most tools, including Stable Diffusion :
Except as set forth herein, Licensor claims no rights in the Output You generate using the Model. You are accountable for the Output you generate and its subsequent uses. No use of the output can contravene any provision as stated in the License.
The license goes on to prohibit any use that “violates any applicable national, federal, state, local or international law or regulation” which would include copyright law.
You own all Assets You create with the Services, to the extent possible under current law. This excludes upscaling the images of others, which images remain owned by the original Asset creators.
And OpenAI (DALL-E 2):
As between the parties and to the extent permitted by applicable law, you own all Input, and subject to your compliance with these Terms, OpenAI hereby assigns to you all its right, title and interest in and to Output.
In terms of copyrighting anything you have created with such a tool, the US Copyright Office has stated that copyright only applies to art created by humans (along with other requirements, like originality):
In cases where non-human authorship is claimed, appellate courts have found that copyright does not protect the alleged creations.
Law is constantly evolving, so this may be successfully challenged in the future. It’s also worth noting that elements of a final product that are not the product of an AI generator (like plot, or dialogue) are still able to be copyrighted even if other elements (like artwork or music) are not.
Can AI Art Generators Use My Copyrighted Art?
The question is not necessarily “can” AI generators use your copyrighted art, but “do” they use your copyrighted art already. The answer to that question, as many artists have found out, is a resounding yes. Above we’ve discussed some methods of opting out of datasets and preventing crawlers from indexing your content, but these techniques ultimately depend on whoever is at the helm respecting your preferences.
You can find out if your art is included in the largest public datasets of images using HaveIBeenTrained.com . Upload one of your better-known artworks or search for your name, artwork title, webcomic, or other creation and take a look. If you see your artwork appear on the website, your art is included in a dataset used by Stable Diffusion and others.
That’s to say nothing of the other generative art applications that do not disclose which datasets are in use (like OpenAI’s DALL-E). You can always try a prompt like “artwork in the style of Your Name” to see if anything familiar shows up.
Upcoming Tools May Help Defeat AI Art Generators
There may be some hope for artists coming in the form of tools that can make it harder for a generative AI to reproduce artwork based on images in a dataset. Unfortunately, these solutions are not here yet (at the time of writing) and there’s no telling how effective they will be in the long term. AI tools evolve quickly, so it’s possible they could evolve to circumvent such safeguards.
The first is Glaze , a project from the University of Chicago that “adds very small changes” to artwork before being uploaded. The developers refer to these changes as a “style cloak” and notes that the artwork appears—to the human eye—nearly identical to the original while causing the AI to misinterpret the style as that of another.
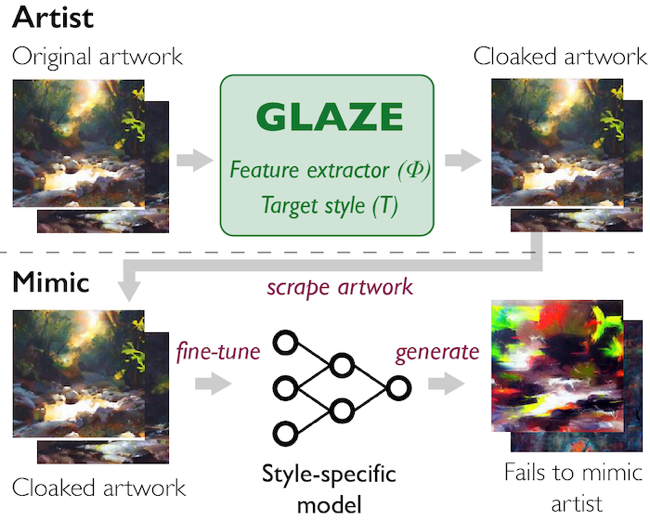
Glaze Project / University of Chicago
Glaze will be released as an application for Mac and Windows, so artwork can be “cloaked” without ever leaving the artist’s computer. Developers say they will not commercialize the tool, so it will be free to use for anyone. The Glaze project looks at the tool as “a necessary first step towards artist-centric protection tools to resist AI mimicry.”
Another technique as outlined in the University of Melbourne’s Pursuit blog describes the subtle use of noise that “changes just enough pixels in an image to confuse AI, and turn it to an ‘unlearnable’ image.” The institution claims to have come up with a technique that exploits a weakness in the models and goes as far as describing tools like Stable Diffusion as “lazy learners.”
This technique has a wide range of potential uses including visual artwork but also audio and photographs that personally identify you. It’s important to recognize that these techniques are still early in terms of development so we’ll have to wait and see what they’re truly capable of.
Rise of the Robots
Generative art apps can create artwork in no time at all, but they aren’t truly creative in the same way that humans are . ChatGPT may be able to write your resume , but you’ll need to proofread it carefully because the chatbot is often confidently wrong .
The bottom line is that the current AI solutions may be useful but they’re also weak .
Also read:
- [New] 2024 Approved Transform Your Win11 Sessions with Advanced Zoom Skills
- [New] 2024 Approved Unlock Full Potential of OBS Studio for Android Devices
- [Updated] Bridging the Gap How to Successfully Export SRT From Premiere for 2024
- 2024 Approved Essential Guide Crafting & Refining Windows 11 Videos
- Adjusting Windows 10'S Lock Screen Duration Settings
- Easy Instructions for Generating Restore Points on Your Windows 10 Device
- Easy Instructions: How to Turn Off Quick Access Button in Microsoft's Latest OS, Windows
- Expert Tips for Accessing Elevated PowerShell/Command Prompt in Windows 11, 8 & 8.1
- Fixing Windows 10 Calculator Issues - Comprehensive Solutions Guide
- How to Repair Broken video files of Blaze Pro 5G on Mac?
- In 2024, How To Change Xiaomi Redmi K70E Lock Screen Clock in Seconds
- In 2024, Integrating CG Central's Luts Into VFX Production Flows
- Progressive Array of Chat-Initiators for Attracting Podcast Audience
- Winterize Windows: Holiday Customization Steps
- Title: Securing Your Visual Content Against Unauthorized Replication by AI-Powered Design Programs
- Author: Edward
- Created at : 2025-01-26 01:21:19
- Updated at : 2025-01-31 08:05:14
- Link: https://vp-tips.techidaily.com/securing-your-visual-content-against-unauthorized-replication-by-ai-powered-design-programs/
- License: This work is licensed under CC BY-NC-SA 4.0.